人工智能基础入门 以软件开发视角理解线性回归模型
在当今软件开发领域,人工智能(AI)已从高深的概念演变为解决实际问题的强大工具。理解AI的基础是将其成功集成到软件应用中的关键,而线性回归模型作为最经典、最直观的机器学习算法之一,是入门AI世界的绝佳起点。本文将从一个软件开发者的角度,探讨人工智能的基础知识,并深入剖析线性回归模型的原理、实现与应用。
一、 人工智能:超越传统编程的范式
传统软件开发遵循“输入-规则-输出”的范式,即开发者需要预知所有情况并编写明确的处理逻辑。而人工智能,特别是机器学习,则是一种“输入-数据-模型-输出”的新范式。其核心是让计算机从大量数据中自动学习规律(模型),并基于此对新数据进行预测或决策。对于软件开发者而言,这意味着从“编写所有规则”转向“设计学习算法并提供高质量数据”。理解这种范式转变是应用AI技术的第一步。
二、 线性回归模型:机器学习的第一块基石
线性回归是用于解决回归问题(预测连续值)的监督学习算法。其思想简单而强大:寻找一个线性方程(模型)来最佳地拟合已知的数据点,从而预测新的未知值。
- 核心概念:
- 假设函数:通常表示为 \( y = wx + b \)(单变量)或 \( y = W^T X + b \)(多变量)。其中,\( y \) 是预测值,\( x \)(或 \( X \))是输入特征,\( w \)(或 \( W \))是权重(模型参数),\( b \) 是偏置项。模型的目标就是找到最优的 \( w \) 和 \( b \)。
- 损失函数:用于衡量模型预测值与真实值之间的差距。在线性回归中,最常用的是均方误差(MSE)。损失函数的值越小,模型拟合得越好。
- 优化算法:如何找到使损失函数最小化的 \( w \) 和 \( b \)?梯度下降法是标准答案。它通过计算损失函数对参数的梯度,并沿梯度反方向迭代更新参数,逐步逼近最优解。这个过程与软件开发中通过迭代调试优化代码性能有异曲同工之妙。
- 软件开发中的实现流程:
- 问题定义与数据准备:明确要预测的目标(如房价、销售额)。收集并清洗数据,处理缺失值和异常值。这是决定模型成败的基础,如同软件开发中的需求分析和数据建模。
- 特征工程:将原始数据转换为模型更能理解的数值特征。例如,将分类数据(如城市名)进行独热编码。这一步极具创造性和工程性,是开发者经验的重要体现。
- 模型训练:使用准备好的数据,通过梯度下降等算法求解模型参数。在现代开发中,开发者很少手动实现该算法,而是借助成熟的库(如Python的Scikit-learn、TensorFlow、PyTorch)来完成。
- 评估与部署:使用未参与训练的测试数据评估模型性能(常用R²分数、均方根误差RMSE)。性能达标后,将训练好的模型(本质是一组\( w \)和\( b \)的参数值)集成到软件系统中,通过API或嵌入式库对外提供预测服务。
三、 从线性回归到现代AI软件开发
理解线性回归不仅是为了掌握一个模型,更是为了构建一套完整的AI开发思维框架:
- 模型即组件:训练好的线性回归模型可以封装成一个独立的、可复用的软件组件(如一个类或微服务),接收输入并返回预测结果。
- 管道化思维:AI项目通常是包含数据预处理、训练、评估、部署的完整流水线。类似CI/CD(持续集成/持续部署),可以构建MLOps管道来自动化这一过程。
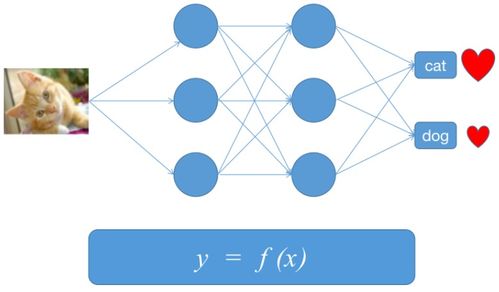
- 超越线性:线性回归假设特征与目标间存在线性关系,但现实世界往往更复杂。这自然引出了对更复杂模型(如多项式回归、决策树、神经网络)的需求。神经网络中的单个神经元就可以看作是一个线性回归单元加上一个非线性激活函数。
结论
对于软件开发者而言,人工智能并非遥不可及的黑魔法。从扎实理解线性回归这样的基础模型开始,就能把握住机器学习的核心脉络——定义问题、处理数据、构建并优化模型、集成部署。它完美地诠释了如何用数据和算法让软件“学会”解决问题。掌握这一基础,开发者便能够更自信地探索更广阔的AI领域,如深度学习、自然语言处理等,并将这些先进能力高效、可靠地转化为实际软件产品的价值。在AI驱动的时代,将线性回归这样的基础模型作为工具箱中的标准件熟练运用,是每一位寻求进步的软件开发者的必备技能。
如若转载,请注明出处:http://www.huiganjiang.com/product/84.html
更新时间:2026-06-19 17:57:09